S3 APIs integrations
S3 is a cloud-based object storage service designed to store and retrieve any amount of data.
Windmill provides a unique resource type for any API following the typical S3 schema.
You can link a Windmill workspace to an S3 bucket and use it as source and/or target of your processing steps seamlessly, without any boilerplate.
See Object Storage for Large Data for more details.
Add an S3 Resource
Here are the required details:
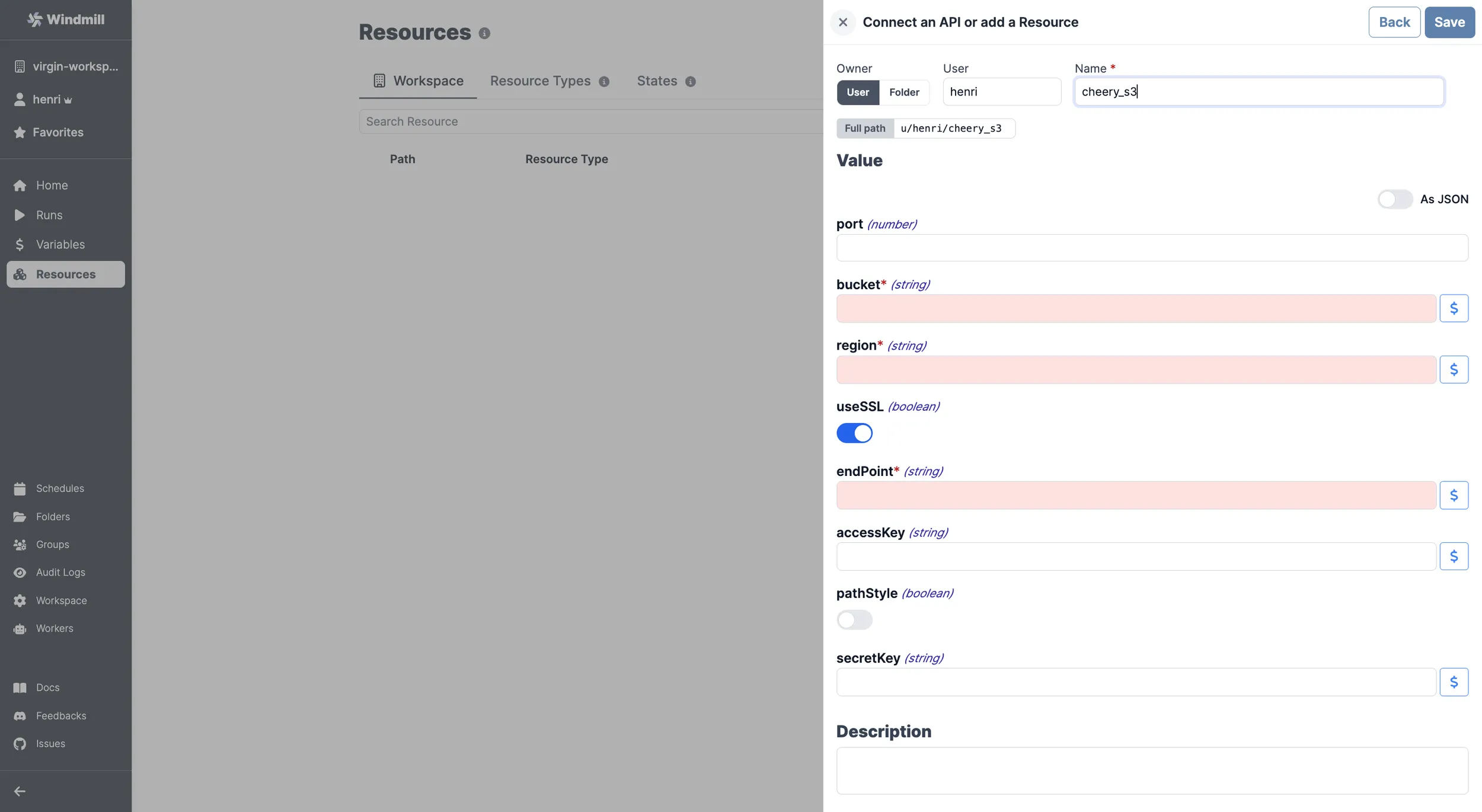
| Property | Type | Description | Default | Required |
|---|---|---|---|---|
| bucket | string | S3 bucket name | true | |
| region | string | S3 region for the bucket | true | |
| useSSL | boolean | Use SSL for connections | true | false |
| endPoint | string | S3 endpoint | true | |
| accessKey | string | AWS access key | false | |
| pathStyle | boolean | Use path-style addressing | false | false |
| secretKey | string | AWS secret key | false |
For guidelines on where to find such details on a given platform, please go to the AWS S3 or Cloudflare R2 pages.
Your resource can be used passed as parameters or directly fetched within scripts, flows and apps.
Connect your Windmill workspace to your S3 bucket or your Azure Blob storage
Once you've created an S3 or Azure Blob resource in Windmill, you can use Windmill's native integration with S3 and Azure Blob, making it the recommended storage for large objects like files and binary data.

Using S3 with Windmill is not limited. What is exclusive to the Enterprise version is using the integration of Windmill with S3 that is a major convenience layer to enable users to read and write from S3 without having to have access to the credentials.
S3/Azure for Python Cache & Large Logs
For large logs storage (and display) and cache for distributed Python jobs, you can connect your instance to a bucket.